Fragebogen und Sampling
Berichte der Arbeitsgruppen
Fragebogen
Die Aufgabe der Gruppe Fragebogen war es die Umfrage sowohl technisch, als auch gestalterisch vorzubereiten. Dieser Abschnitt zeigt auf wie der Fragebogen entstanden ist und welche Aspekte dabei am wichtigsten waren. Für die Erstellung des Fragebogens haben sich drei Aspekte als besonders wichtig erwiesen:
(1) Technischer Aspekt
Der Fragebogen wurde mit der Plattform SoSciSurvey erstellt und wird auch dort gehostet. Funktionen wie die Steuerung, Weiterleitung und Filterung innerhalb des Fragebogens wurden über PHP und HTML-Elemente umgesetzt.
Die erhobenen Daten werden anonymisiert auf SoSciSurvey gespeichert. Der Datenschutz wird durch Server in Deutschland sichergestellt. Dadurch gelten sowohl die Datenschutz-Grundverordnung (DSGVO) als auch das Bundesdatenschutzgesetz (BDSG).


(2) Visueller Aspekt
Unser Ziel war es, ein konsistentes und angenehmes Layout zu gestalten, das sich durch den gesamten Fragebogen zieht. Besonders wichtig war dabei, dass Fragen und Antwortmöglichkeiten übersichtlich angeordnet sind, sich nicht überlappen und gut lesbar bleiben. Dabei wirkt ein klar strukturiertes Design der Monotonie entgegen. Außerdem reduziert es Verständnisfragen und erleichtert den Ablauf.
(3) Methodischer Aspekt
Im Mittelpunkt eines Fragebogens stehen der Aufbau und die Sprache, da beide die Verständlichkeit und Vertrauenswürdigkeit beeinflussen. Der Fragebogen ist klar, eindeutig und neutral formuliert. Damit lassen sich Missverständnisse vermeiden, wodurch die Ergebnisse besser vergleichbar bleiben.
Ein gut strukturierter Aufbau hilft den Teilnehmenden sich zu orientieren. Das steigert die Motivation und wirkt gleichzeitig der Monotonie entgegen, was besonders bei längeren Fragebögen wie unserem wichtig ist.
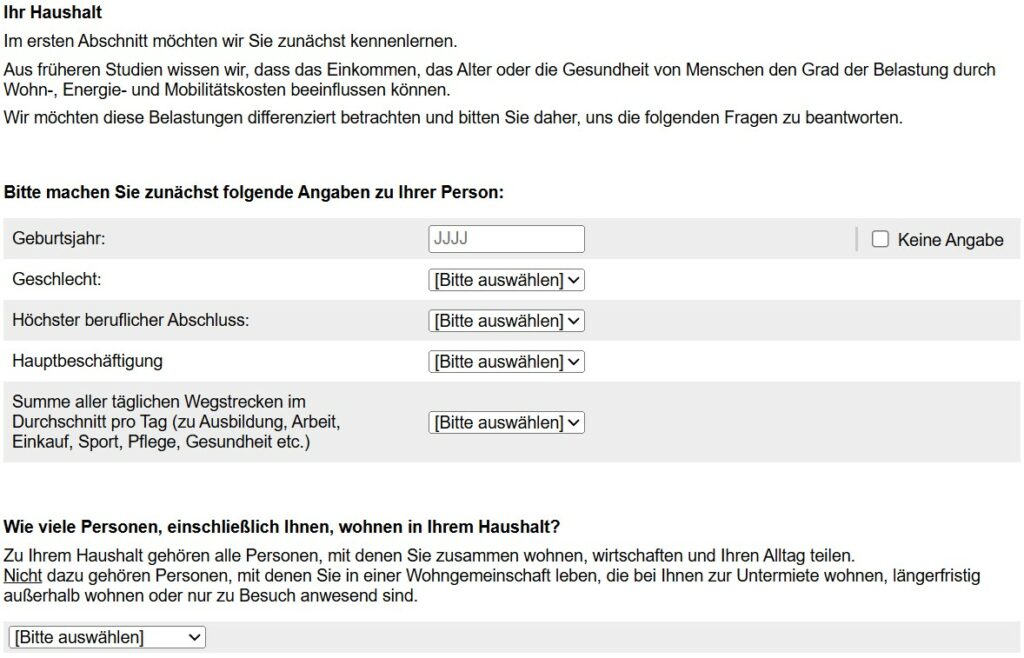
Vorgehen bei der Erstellung des Fragebogens
In der Literatur finden sich zahlreiche Regeln und Prinzipien zur Erstellung von Fragebögen. Ein klarer Einstieg ist dabei wichtig, da darin die grundlegenden Verständnisfragen vorab geklärt werden. So können sich die Teilnehmenden während der Bearbeitung des Fragebogens vollständig auf die Inhalte konzentrieren.
Zu Beginn werden der Zweck und das Ziel der Forschung, als auch die Auswahl der Zielgruppe erläutert. Zusätzlich werden Hinweise zu Kontaktmöglichkeiten bei Rückfragen, zur Freiwilligkeit der Teilnahme und zur Anonymität genannt. Abschließend werden die wichtigsten Informationen zum Datenschutz transparent dargestellt.
Der Fragebogen ist klar in thematische Abschnitte gegliedert. Die Themen Wohnen, Energie und Mobilität waren in unserem Projekt von Beginn an festgelegt und deutlich gekennzeichnet. Zwischen den einzelnen Themenblöcken werden verständliche Übergänge formuliert, die den inhaltlichen Wechsel erklären und die Motivation der Teilnehmenden aufrechterhalten. Beim Übergang zwischen den Themen Wohnen, Energie und Mobilität wird zum Beispiel kurz erläutert, was darunter verstanden wird und warum dieses Thema relevant ist.
Die ersten Fragen eines Fragebogens sind bewusst einfach gehalten. Sie dienen als Einstieg, senken die Hemmschwelle und erleichtern den Beginn. Wir beginnen daher mit demographischen Angaben wie dem Geburtsjahr und dem Geschlecht, da diese Informationen in der Regel unkompliziert und vertraut sind.
Ein Wechsel zwischen einfachen Fragen und komplexeren Aufgaben, wie etwa Ranglisten oder Bewertungsfragen, trägt dazu bei, die Aufmerksamkeit aufrechtzuerhalten. Zur Auflockerung setzen wir visuelle Elemente ein, zum Beispiel Abbildungen unterschiedlicher Gebäudetypen.
Lange oder monotone Skalen werden möglichst vermieden oder mit kürzeren, abwechslungsreichen Fragetypen kombiniert. Zusätzlich wechseln sich Wissens-, Einstellungs- und Bewertungsfragen gezielt ab, um den Fragebogen lebendig und nutzerfreundlich zu gestalten.
Nach sensiblen Themen setzen wir gezielt sogenannte "Pufferfragen" ein. Diese helfen dabei, die Befragten zu entlasten und einen inhaltlichen Abstand zu schaffen. Ein Beispiel hierfür ist der Übergang von Fragen zum Einkommen hin zu allgemeineren Fragen zur Stadt oder Gemeinde, in der die Befragten leben.
Heikle, sensible oder besonders umfangreiche Themen werden bewusst nicht an den Anfang gestellt, sondern im mittleren Teil des Fragebogens platziert, wenn bereits ein gewisses Vertrauen aufgebaut wurde. Auch längere oder einseitige Fragen befinden sich überwiegend in diesem Abschnitt.
Insgesamt folgt der Fragebogen einer klaren, strukturierten Gliederung, bei der die Themen logisch aufeinander aufbauen. Am Ende der Befragung wird den Teilnehmenden die Möglichkeit gegeben, Anmerkungen zu machen. Der Fragebogen schließt mit einem kurzen Dank für die Teilnahme.
Nach der Fertigstellung unseres Fragebogens wurde ein Pretest durchgeführt, bei dem der Fragebogen von Testpersonen ausgefüllt und kritisch bewertet wurde. Die dabei gewonnenen Rückmeldungen, Hinweise auf Verständnisschwierigkeiten und Verbesserungsvorschläge flossen direkt in die Überarbeitung ein. Auf diese Weise konnten Struktur, Formulierungen und Nutzerfreundlichkeit weiter verbessert werden.
Die PDF-Version unseres Fragebogens aus dem Pretest:
Döring, Nicola (2023): Forschungsmethoden und Evaluation in den Sozial- und Humanwissenschaften, 6. Auflage, Springer Wiesbaden.
Köstner, Hariet (2023): Empirische Forschung in den Wirtschafts- und Sozialwissenschaften klipp & klar. Springer Gabler Wiesbaden.
Möhring, Wiebke, Schütz, Daniela (2019): Die Befragung in der Medien- und Kommunikationswissenschaft-Eine praxisorientierte Einführung. Springer Wiesbaden.
Petersen, Thomas (2014): Der Fragebogen in der Sozialforschung. UVK Verlagsgesellschaft, Konstanz.
Reinders, H., Bergs-Winkels, D., Prochnow, A., & Post, I. (Hrsg.). (2022). Empirische Bildungsforschung: Eine elementare Einführung (Neuauflage). Springer Wiesbaden.
Taherdoost, Hamed (2022): Designing a Questionnaire for a Research Paper: A Comprehensive Guide to Design and Develop an Effective Questionnaire.
Berichte der Arbeitsgruppen
Sampling
Was ist "Sampling"
Sampling ist in der Sozialforschung die systematische Auswahl einer Teilmenge (Stichprobe) aus einer Grundgesamtheit, um aus dieser Teilmenge wissenschaftlich fundierte Aussagen über die Gesamtpopulation treffen zu können.
Da es in der Praxis nicht möglich ist, alle Gemeinden vollständig zu erfassen, wird eine Stichprobe gezogen, die die relevanten Merkmale der Grundgesamtheit möglichst gut abbildet. Sampling ist somit zentral für die Qualität einer Studie, da Fehler in der Stichprobenziehung direkte Auswirkungen auf die Aussagekraft der Ergebnisse haben.
Warum braucht es Sampling
Die Bedeutung von Sampling liegt insbesondere in der Sicherstellung von Repräsentativität und Vergleichbarkeit. Da es nicht möglich ist, so viele Menschen zu befragen, dass die Umfrage repräsentativ ist, wurde entschieden, Vorüberlegungen anzustellen. Das ist Theoretical Sampling. Dabei werden Untersuchungseinheiten nicht zufällig, sondern schrittweise auf Grundlage bereits gewonnener Erkenntnisse und Hypothesen ausgewählt.
Ziel ist es, durch den Vergleich der unterschiedlichen Gemeinden theoretische Konzepte weiterzuentwickeln und einzelne auszuwählen, um dort die Befragungen durchzuführen.
Praktische Einschränkungen
Praktische Einschränkungen bestanden beispielsweise in der
- Verfügbarkeit regionalstatistischer Daten,
- zeitlichen Ressourcen sowie der
- Vergleichbarkeit von Indikatoren zwischen Gemeinden in Thüringen und Sachsen-Anhalt.
Die Überlegungen bezogen sich darauf, welche strukturellen Rahmenbedingungen einen Einfluss auf Wohn- und Energiekostenbelastungen haben könnten. Nach der Auswahl der Rahmenbedingungen (Indikatoren) folgte die Sortierung der Gemeinden.
Clusteranalyse
Ein zentrales methodisches Instrument dafür war die Clusteranalyse. Die Clusteranalyse ist ein Verfahren, mit dem Gemeinden anhand ausgewählter Indikatoren in Gruppen (Cluster) eingeteilt werden, sodass sich die Elemente
- innerhalb eines Clusters möglichst ähnlich und
- zwischen den Clustern möglichst unterschiedlich sind
(vgl. Backhaus et al., Multivariate Analysemethoden).
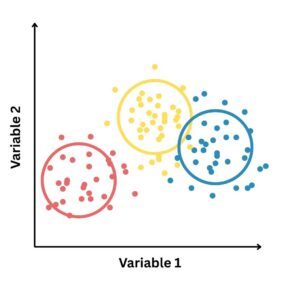
Der Zweck der Clusteranalyse bestand darin, einen strukturierten Überblick über die Gemeinden zu erhalten und sie anhand sozioökonomischer und infrastruktureller Merkmale zu charakterisieren. So sollen Gemeinden identifiziert werden, in denen die Wahrscheinlichkeit hoch oder niedrig ist, Menschen mit höherer oder geringerer Betroffenheit von Wohn- und Mobilitätskostenbelastungen anzutreffen.
Ziel der Clusteranalyse war somit die systematische Ordnung und Typisierung von Gemeinden anhand ausgewählter Indikatoren. Dies diente nicht nur der Übersicht, sondern auch der gezielten Fallauswahl für weiterführende Analysen.
Vorgehen bei der Analyse in 3 Schritten
Nach links swipen um alle Schritte zu sehen
Schritt 1
Unterscheidung der Gemeinden nach regionalstatistischen Raumtypen des Bundesinstituts für Bau-, Stadt- und Raumforschung
Schritt 2
Ermittlung der durchschnittlichen Kaufkraft der jeweiligen Gemeinden
Schritt 3
Prüfung der Erreichbarkeiten der Gemeinden
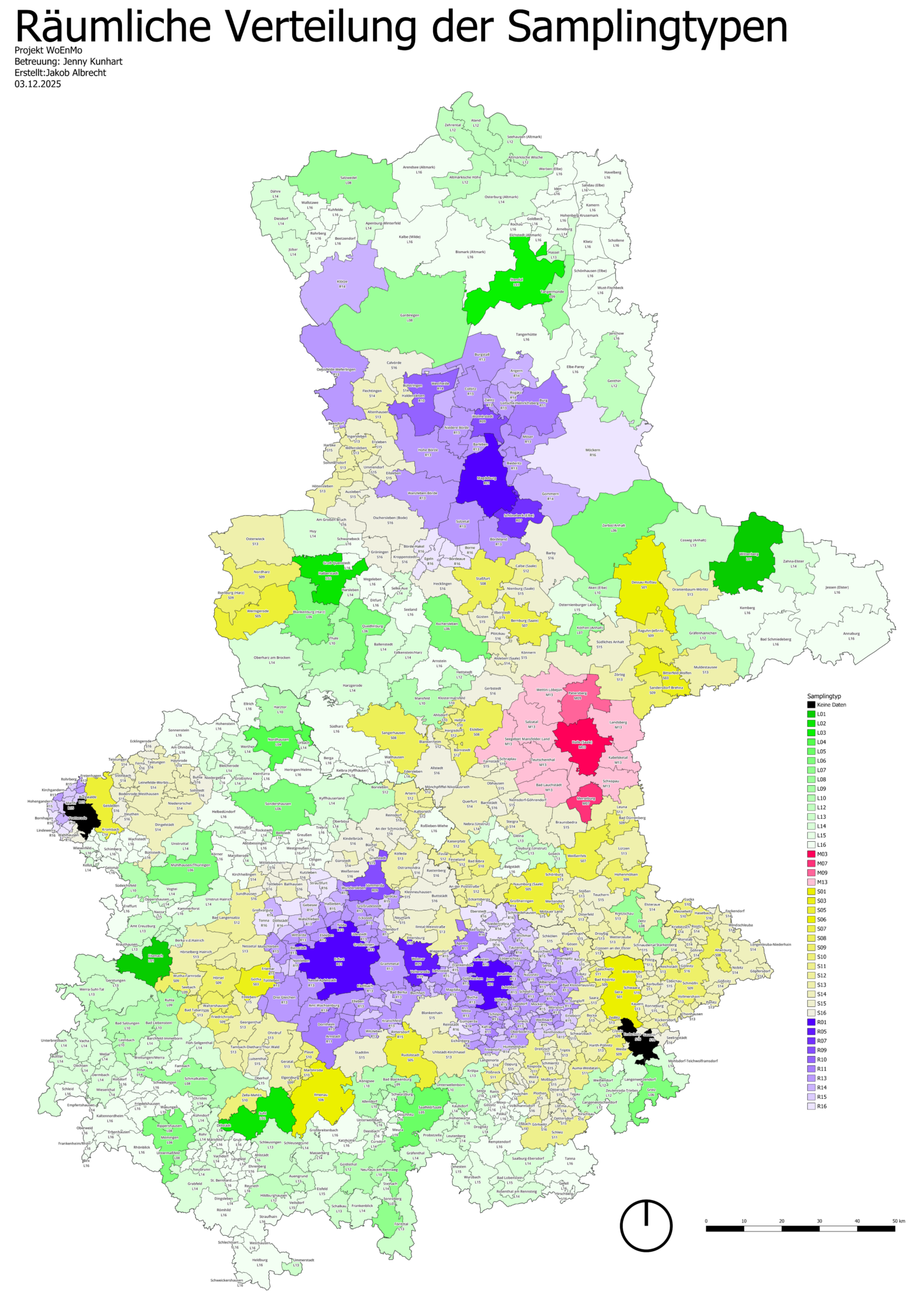
Unterscheidung der Gemeinden nach nach Raumtypen
Der erste Analyseschritt bestand in der Unterscheidung der Gemeinden nach regionalstatistischen Raumtypen des Bundesinstituts für Bau-, Stadt- und Raumforschung; sie werden auch RegioStar 17 (2023) genannt. Diese Einteilung unterscheidet Gemeinden in vier grundlegende Raumtypen:
- Metropolregion (rot),
- Regiopolregion (blau),
- stadtnahe Region (gelb) und
- ländliche Region (grün).
Diese Raumtypen werden zusätzlich nach Zentralitätsstufen differenziert, sodass insgesamt 17 Regionstypen entstehen. Jede Raumeinheit besitzt eine spezifische Kennziffer. Die Auswahl dieses ersten Indikators erfolgte, da räumliche Lage und Zentralität maßgeblich mit
- Infrastruktur,
- Arbeitsmarktzugang,
- Mietniveau und
- Mobilitätsanforderungen zusammenhängen.
Somit bildet der Raumtyp die Grundlage für mögliche Unterschiede in Wohn- und Mobilitätskostenbelastungen.
Ermittlung durchschnittlicher Kaufkraft der Gemeinden
Im zweiten Schritt wurde die durchschnittliche Kaufkraft der jeweiligen Gemeinden betrachtet und mit dem Durchschnitt aller Gemeinden im selben Bundesland verglichen.
- Für Thüringen lag der Durchschnitt bei 26.687,57 €,
- für Sachsen-Anhalt bei 27.085,27 €.
Gemeinden mit unterdurchschnittlicher Kaufkraft wurden von solchen mit überdurchschnittlicher Kaufkraft unterschieden.
Der Indikator Kaufkraft wurde gewählt, weil er das frei verfügbare Einkommen der Menschen widerspiegelt, ohne ihre Lebenserhaltungskosten (Miete, Lebensmittel etc.) mit einzubeziehen.
Das ermöglicht es, die finanziellen Belastungen der Menschen in verschiedenen Gemeinden zu vergleichen. Regionen mit geringerer Kaufkraft weisen tendenziell ein höheres Risiko für finanzielle Belastungen auf.
Prüfung der Erreichbarkeit der Gemeinden
Der dritte Schritt war die Prüfung der Erreichbarkeiten, insbesondere der Entfernung zu
- Fernverkehrsbahnhöfen,
- ÖPNV-Haltestellen und
- Autobahnen,
…gemessen in Autominuten.
Die Erreichbarkeit ist ein zentraler Indikator für Mobilität und potenzielle Mobilitätskosten.
Eine schlechte Anbindung kann zu höheren Mobilitätsausgaben führen, insbesondere wenn es keine Alternative zum Auto gibt. Gleichzeitig beeinflusst die Verkehrsanbindung auch die Attraktivität und damit das Mietniveau einer Region.
Fazit
Zusammenfassend diente das gewählte Sampling-Verfahren in Kombination mit der Clusteranalyse dazu,
Gemeinden systematisch zu charakterisieren, strukturell zu ordnen und vergleichbar zu machen.
Durch die Kombination aus Raumtypen, Kaufkraft und Erreichbarkeit der Verkehrsinfrastruktur konnten Gemeinden identifiziert werden, in denen die Wahrscheinlichkeit unterschiedlich hoch ist, Menschen mit starker oder geringer Wohn-, Energie- und Mobilitätskostenbelastung zu finden.
Glaser, Barney G. & Strauss, Anselm L. 1967: The Discovery of Grounded Theory: Strategies for Qualitative Research. Chicago: Aldine.
Backhaus, Klaus; Erichson, Bernd; Gensler, Sonja; Weiber, Thomas; Weiber, Rolf 2021: Multivariate Analysemethoden: Eine anwendungsorientierte Einführung. 16. Aufl. Berlin: Springer Gabler.
Bundesinstitut für Bau-, Stadt- und Raumforschung 2023: RegioStar 17 – Raumtypologie der Gemeinden 2023. Bonn: BBSR.
Menu